Flink简介
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
批处理特点是有界,持久,大量,一般做离线计算,如收集一天的数据,然后进行计算。
流处理是无界的,实时进行的,类似于用户的访问日志是会24小时不断产生的。
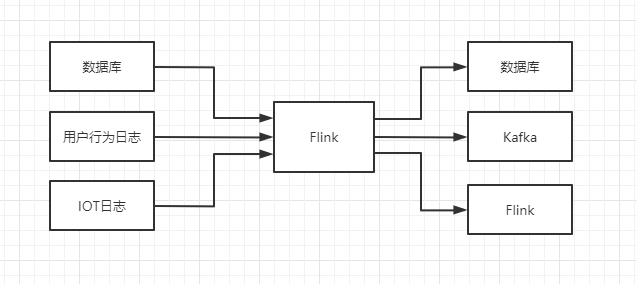
Flink架构简单来说,就是通过收集各种实时数据,通过数据库,Kafka等中间件发送到Flink流处理程序中,多条流可以并行高效方便的进行分组、合并、过滤等计算,然后得到结果返回到其他中间件系统中进行分析,统计等。
Flink简单上手体验
- 先在IDEA中创建一个标准Maven工程,pom加入如下依赖:
1 |
|
创建一个WordCount批处理程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class WordCountBatch {
public static void main(String[] args) {
//1. 创建Flink执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2. 直接从本地文件中读取一个文件
DataSet<String> text = env.readTextFile("/path/to/file");
//3. 按照Tokenizer里的规则进行切分输出,输出的格式是(单词,1)
// 然后通过下标0的元素,也就是词本身进行分组,分组后将下标2进行计数,达到wordcount的效果
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new Tokenizer())
.groupBy(0)
.sum(1);
//4. 输出到控制台
counts.print();
}
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
//1. 将读取到的记录按照空格进行分割,并转小写
String[] tokens = value.toLowerCase().split(" ");
//2. 将每个单词遍历,转成元组返回出去
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}
}创建一个流处理WordCount程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class WordCountKafka {
public static String kafkaServers = "hadoop001:9092,hadoop002:9092,hadoop003:9094";
public static void main(String[] args) throws Exception {
//1. 准备基本数据流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2. 接收kafka数据,并转换成DataStream流
String topic = "wordcount_topic";
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaProducer<String>(kafkaServers, topic, new SimpleStringSchema());
DataStreamSource<String> wcStream = env.addSource(kafkaSource);
//3. 将接收到的Kafka流按照批处理的程序一样进行分组&求和
DataStream<Tuple2<String, Integer>> wordCountDataStream =
wcStream.flatMap(new Tokenizer())
.groupBy(0)
.sum(1);
//4. 输出并执行,流处理程序需要execute一下
wordCountDataStream.print();
env.execute("wordCount Kafka task.");
}
}
Flink环境搭建
下载页面:https://flink.apache.org/downloads.html
单机模式
下载程序到CentOS机器上
1
2cd /opt/software
wget https://apache.claz.org/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.11.tgz解压到软件安装目录下
1
2
3
4
5
6
7
8
9
10
11
12# 解压并重命名
tar xzf flink-*.tgz -C /opt/module
mv /opt/module/flink-* /opt/module/flink
# 运行,机器需要有JDK环境
/opt/module/flink/bin/start-cluster.sh
# 输出日志检查是否正在运行中
tail /opt/module/flink/log/flink-*-jobmanager-*.log
# 输出如下日志了说明运行成功
INFO ... - Starting web info server for JobManager on port 8081访问web ui界面进行操作
1
http://ip-addr:8081

- 运行一个内置的示例WordCount
1
2
3
4
5# 运行任务
./bin/flink run examples/streaming/WordCount.jar
# 查看结果
tail log/flink-*-taskexecutor-*.out
或者登录web ui 界面,选择Task Managers查看结果
集群模式
编辑conf/flink-conf.yaml文件,将jobmanager.rpc.address: localhost配置修改为
1
jobmanager.rpc.address: hadoop001
编辑conf/workers文件,添加如下内容
1
2hadoop002
hadoop003将hadoop001的flink目录拷贝到其他两台机器
1
2scp -r /opt/module/flink root@hadoop002:/opt/module/
scp -r /opt/module/flink root@hadoop003:/opt/module/此时再执行启动脚本就能启动Flink集群环境了
1
/opt/module/flink/bin/start-cluster.sh

Flink on yarn 模式
此模式依赖Yarn集群来调度Flink程序,此模式应用最多,可充分利用集群资源,复用当前Hadoop集群,可同时执行MR与Flink任务,方便管理维护。
per job模式
每次提交任务都会创建一个新集群,每个任务之间互相独立不影响,任务执行完成后集群自动取消,不占额外资源,资源利用率最大,生产推荐使用。执行如下命令进行启动:1
2# 以per job的模式在yarn上开辟flink集群运行wordcount程序
/bin/flink run -m yarn-cluster ./examples/batch/WordCount.jarsession模式
提前初始化Flink集群,此集群会长驻在Yarn集群中,无论有没有任务在运行,提交Flink任务的时候是多个任务提交到此一个Flink集群中。1
2
3
4
5
6
7
8
9
10
11# 启动集群
#-n taskManager数量
#-s 每个taskManager的slot数量(默认一个slot一个core)
#-jm jobmanager使用内存
#-tm 每个taskmanager的内存
#-nm 集群名字
#-d 后台运行
./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm yarn-session-task-cluster -d
# 运行一个Flink任务进行测试
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hadoop001:8020/input/* -output hdfs://hadoop001:8020/output运行中的问题
a. 报如下异常:
1 | java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation. |
参考官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/hadoop.html, 执行如下命令或者在./bin/flink文件中增加。
1 | export HADOOP_CLASSPATH=`hadoop classpath` |
b. 提示内存不够
1 | Maximum Memory: 1024MB Requested: 1600MB. Please check the 'yarn.scheduler.maximum-allocation-mb' and the 'yarn.nodemanager.resource.memory-mb' configuration values |
需要调大YARN的yarn.scheduler.maximum-allocation-mb和yarn.nodemanager.resource.memory-mb配置,再重启集群。
c. 提示没有HDFS权限
1 | Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x |
把HDFS的dfs.permission权限检查关闭就完事了,但是这样会有不可控的风险。可以在HDFS中指定特定的用户进行写操作。
Flink API
Flink目前有四种API,分别如下:
- 低级API: 对时间和状态最细粒度控制,易用性差,适合处理复杂事件。
- 核心API: DataSet和DataStream相关API,是对低级API的封装,简单易用应用广泛。
- Table API: 将数据流模拟成表的结构,可以通过SELECT,JOIN等方法直接操作流。
- SQL API: 可以直接用SQL查询模拟成表的数据流。
Environment 环境上下文
getExecutionEnvironment 根据当前执行环境是本地环境还是集群环境创建对应的执行上下文环境对象。
1
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
创建流执行上下文环境
1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
创建本地执行上下文环境,并指定并行度
1
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(4);
获取远程集群执行环境,并提交jar包
1
StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("hadoop001", 6123, "C://WordCount.jar");
DataSource 数据源
从集合读取数据
1
2DataStream<Integer> nums = env.fromElements(1,2,3,4,5,6,7,8,9);
DataStream<String> nums2 = env.fromCollection(Arrays.asList("xiaozhou", "hello"));从文件读取数据
1
DataStream<String> fileDs = env.readTextFile("/opt/hello.txt");
从socket中读取
1
DataStream<String> socketDs = env.socketTextStream("localhost", "1000");
从Kafka中读取
1
2
3
4
5Properties properties = new Properties();
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServers);
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<String>(topic, new SimpleStringSchema(), properties);
DataStream<String> kafkaDs = env.addSource(kafkaConsumer);自定义DataSource
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class SayHello implements SourceFunction<String> {
private boolean running = true;
public void run(SourceContext<String> ctx) throws Exception {
int i = 0;
while(running) {
ctx.collect("hello " + i);
Thread.sleep(1000L);
}
}
public void cancel() {
this.running = false;
}
}
Transform 转换算子
map,从一个数据流转换为另一个流,比如从String转为Student,每条输入对应一条输出。
1
2
3
4
5
6
7
8stuDs.map(new MapFunction<String, Student>() {
public Student map(String value) {
return JSON.parseObject(value, Student.class);
}
});
//也可以使用Lambda方式
stuDs.map(value -> JSON.parseObject(value, Student.class));filter,过滤器,过滤不需要的数据
1
2
3
4
5
6DataStream<String> filterDs = strDs.filter(new FilterFunction<String>() {
public boolean filter(String value) throws Exception {
//过滤字符串长度不为2的
return value.length() == 2;
}
});flatMap,与map类似,但是flatMap的输出可以是0 ~ 任意个,可以在实现方法中定义自己的逻辑。实际上flatMap同时具有map和filter的功能,没有完全替换是因为map和filter的语义上更明确,可读性更高。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataSource<String> dataSource = env.fromElements("hello xiaozhou", "hello world", "hello xiaozhou");
FlatMapOperator<String, String> flatMapOperator = dataSource.flatMap(new FlatMapFunction<String, String>() {
public void flatMap(String s, Collector<String> collector) throws Exception {
String[] strs = s.split(" ");
for (String str : strs) {
if(!str.equals("hello")) {
collector.collect(str);
}
}
}
});
flatMapOperator.print();
env.execute();
}keyBy,分组操作,将单个DataStream转换为多个不相交的KeyedStream流,每个分区包含具有相同key的元素,内部以Hash实现。可以通过
sum(), min(), max(), minBy(), maxBy()进行聚合计算。
1 | //通过json对象中的省份参数进行分组 |
Reduce聚合操作,将KeyedStream -> DataStream,对每个key分区进行合并,并将所有分区数据输出
1
2
3
4
5
6
7
8//对将省份分组数据进行聚合,将销售额进行累加并返回一条整流
SingleOutputStreamOperator<ProvinceSaleData> reduce = keyedDs.reduce(new ReduceFunction<ProvinceSaleData>() {
public ProvinceSaleData reduce(ProvinceSaleData one, ProvinceSaleData two) throws Exception {
one.setAmount(one.getAmount() + two.getAmount());
return one;
}
});connect连接操作,连接两个保持他们类型的数据流到ConnectedStream中,两个流的数据类型可以不同。
union操作,合并多个流,新的流会包含所有流中的数据,合并的流的类型必须一致。
coMap和coFlatMap,在ConnectedStream中使用,类似map和flatMap操作。
函数
UDF函数
自定义函数,可以按照自己的需求更加细粒度的控制流
1 | DataStream<String> flinkTweets = tweets.filter(new FlinkFilter("flink")); |
匿名函数
1 | DataStream<String> flinkTweets = tweets.filter(tweet -> tweet.contains("flink") ); |
富函数
所有Flink函数类都有对应的富函数版本,富函数功能增强了,可以拿到运行的上下文环境,并拥有open,close,getRuntimeContext的生命周期。
1 | public class MyRichFilterFunction extends RichFilterFunction<String> { |
Sink 输出操作
sink可以将计算的数据输入到Flume,Redis,ES,Kafka等中间件中,再进行下一步计算。
- Kafka操作
先添加pom依赖
1 | <dependency> |
代码调用
1 | ds.addSink(new FlinkKafkaProducer<String>(kafkaServers, topic, new SimpleStringSchema())); |
- Redis操作
先添加pom依赖1
2
3
4
5<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
定义一个Redis的mapper类,定义保存到Redis时调用的命令
1 | public static class MyRedisMapper implements RedisMapper<Student>{ |
代码调用
1 | //定义Jedis的连接配置 |
- ES操作
添加pom依赖
1 | <dependency> |
定义一个ES的sink方法
1 | public static class MyEsSinkFunction implements ElasticsearchSinkFunction<Student> { |
调用
1 | //配置ES http连接 |
- 自定义JDBC Sink
添加pom
``pom
1 |
|