上一步安装好了CM后,我们就可以进CM管理后台进行添加服务,安装组件的操作了
添加其他服务器
1.进入到All Host界面下
此时列表下只有hadoop001这台机器,点击Add Hosts来新增其他机器

2.选择添加hosts到我们选定的集群里

3.直接搜索出其他两台机器并选中添加
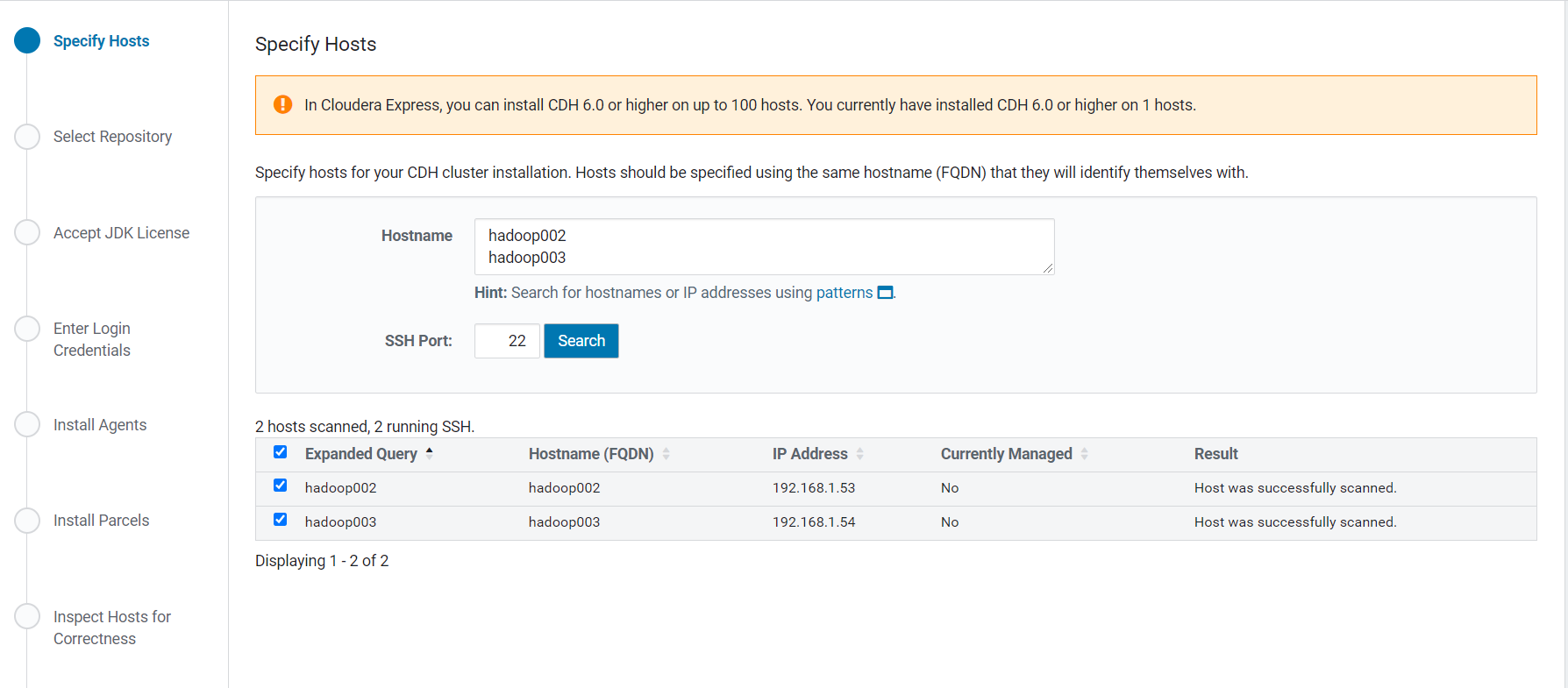
4.选择自定义本地仓库
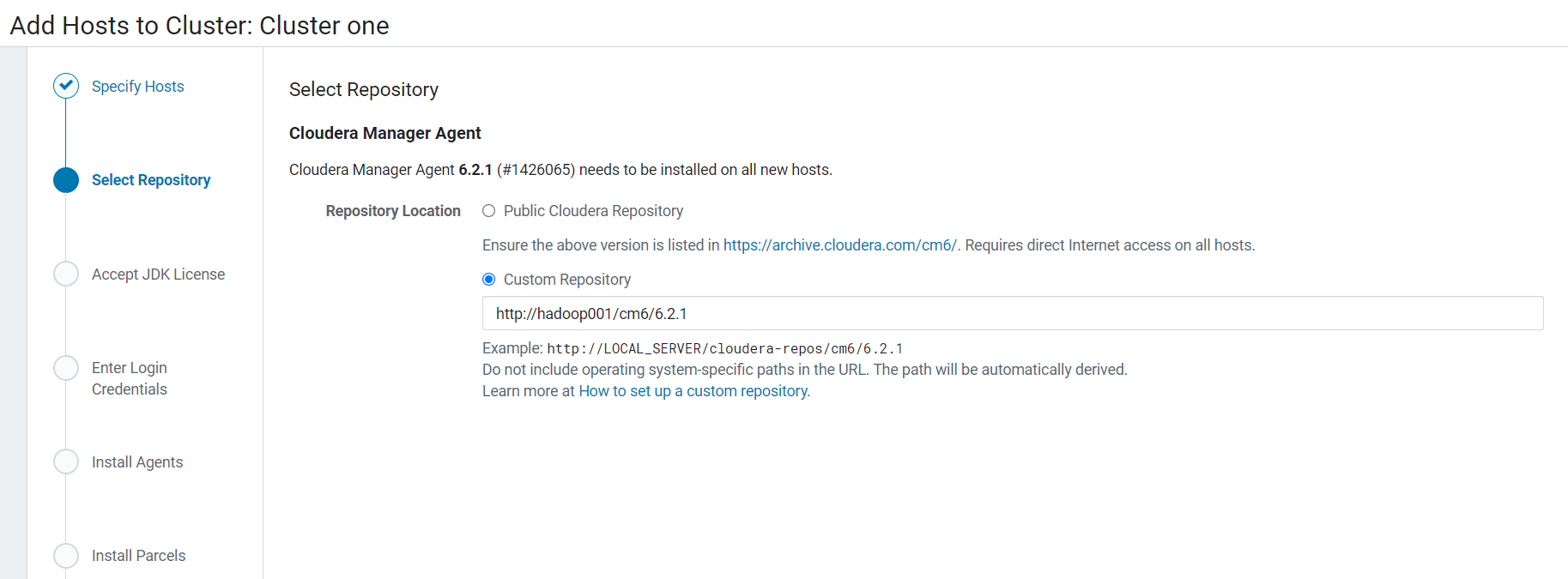
5.选择安装Oracle的JDK

6.配置root的密码

7.等待agents安装成功

8.等待包的下载,分发,解压与激活

9.检查主机

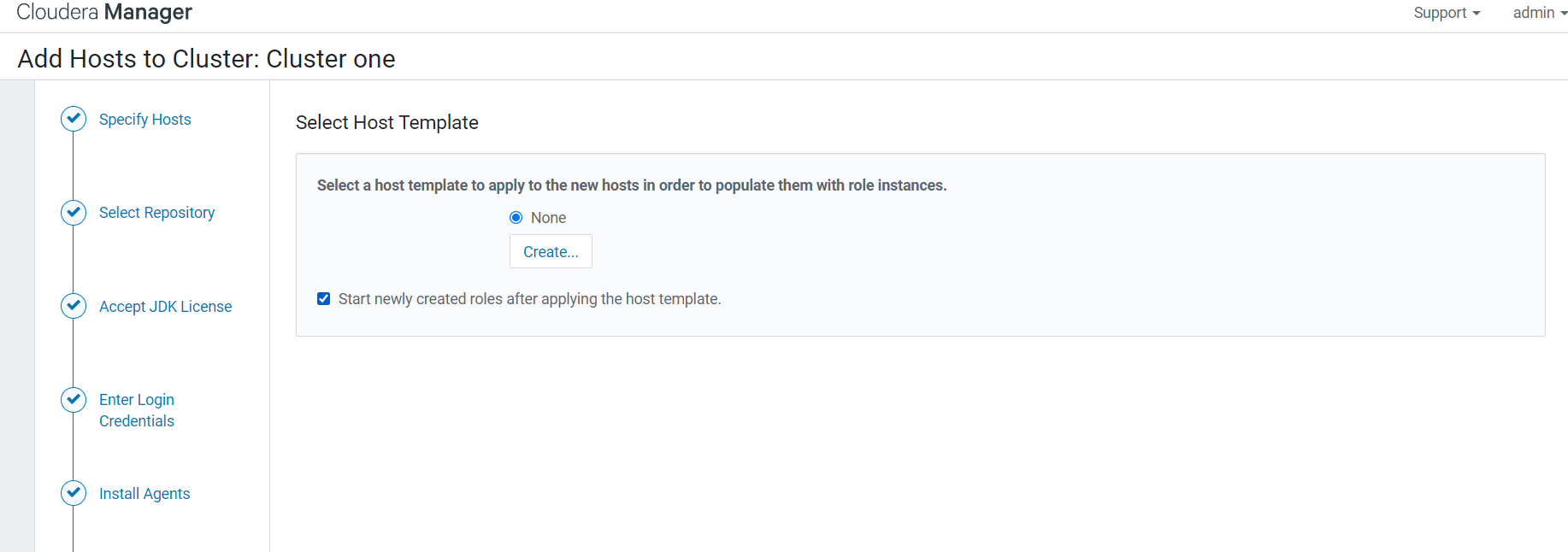
10.选择host模板,默认就好了
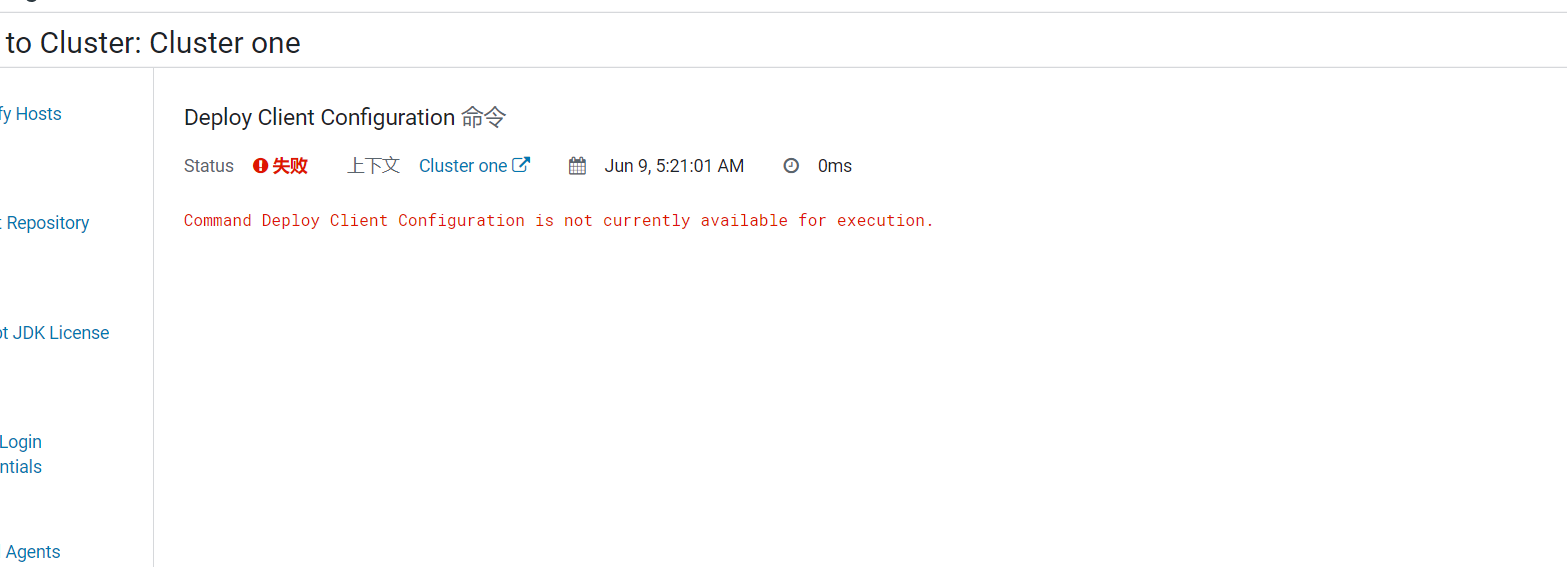
11.命令部署客户端配置有问题,直接忽略这个问题就好了
Cloudera Management Service安装
1.进入hadoop001:7180/cmf/home下,点击Add按钮下的Add Cloudera Management Service
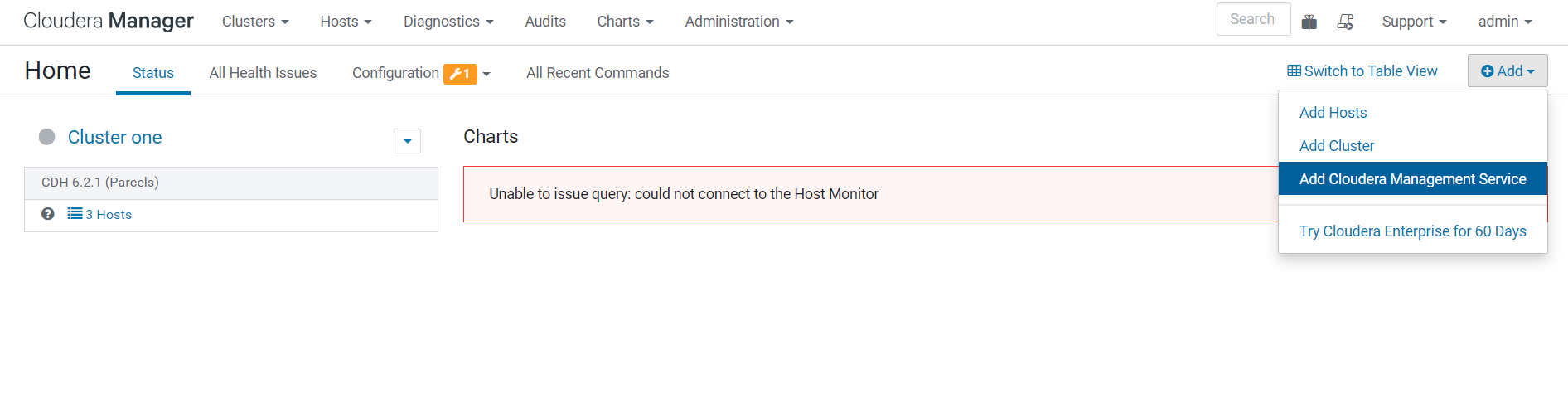
2.选择监控服务安装在哪台机器上,可以按机器的实际情况去调配
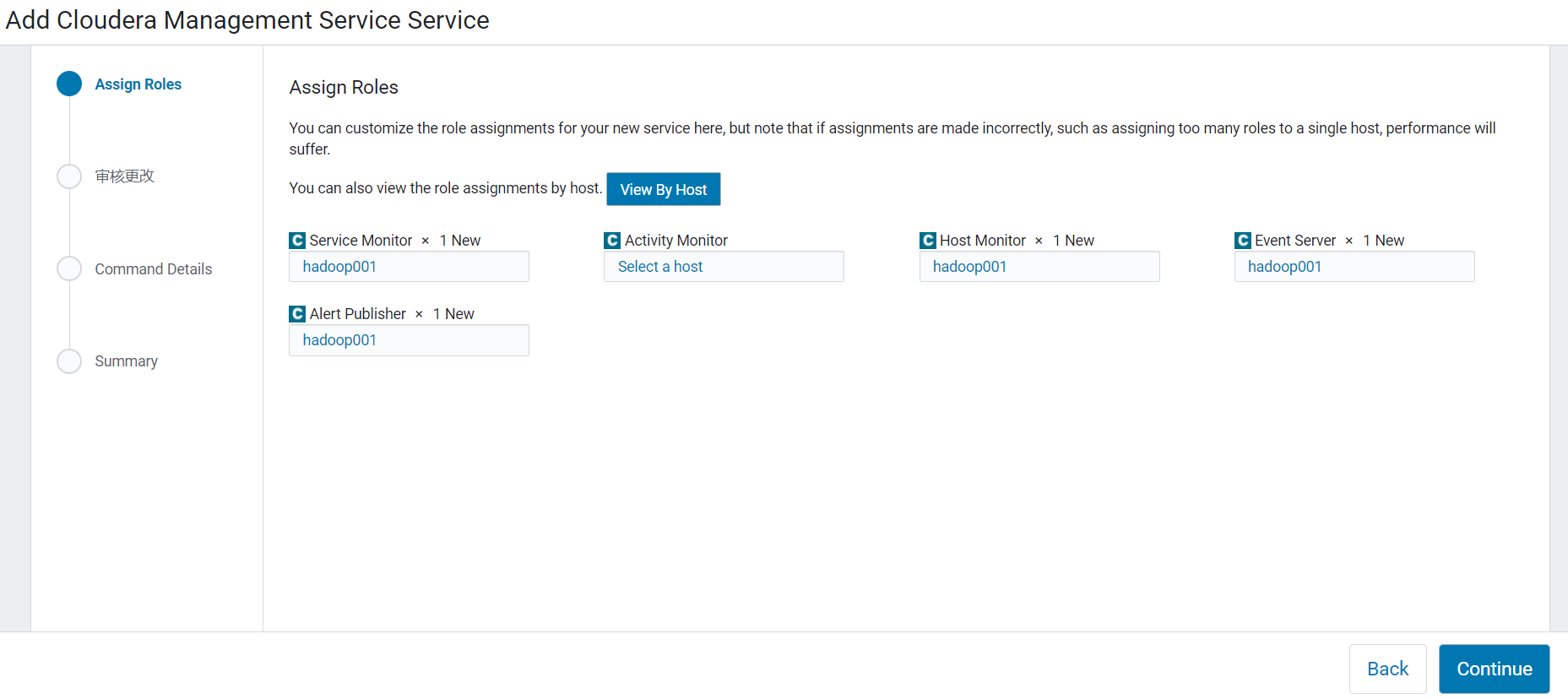
3.配置邮箱预警,配置监控器的本地存储目录
配置本地存储目录需要创建文件夹并赋予权限
1 | mkdir -p /var/lib/cloudera-host-monitor |

4.等待安装成功

5.安装成功后,我们在集群状态里就能看到图表的监控在运行了

HDFS安装
1.进入集群中选择Actions -> Add Service

2.在列表中选中HDFS

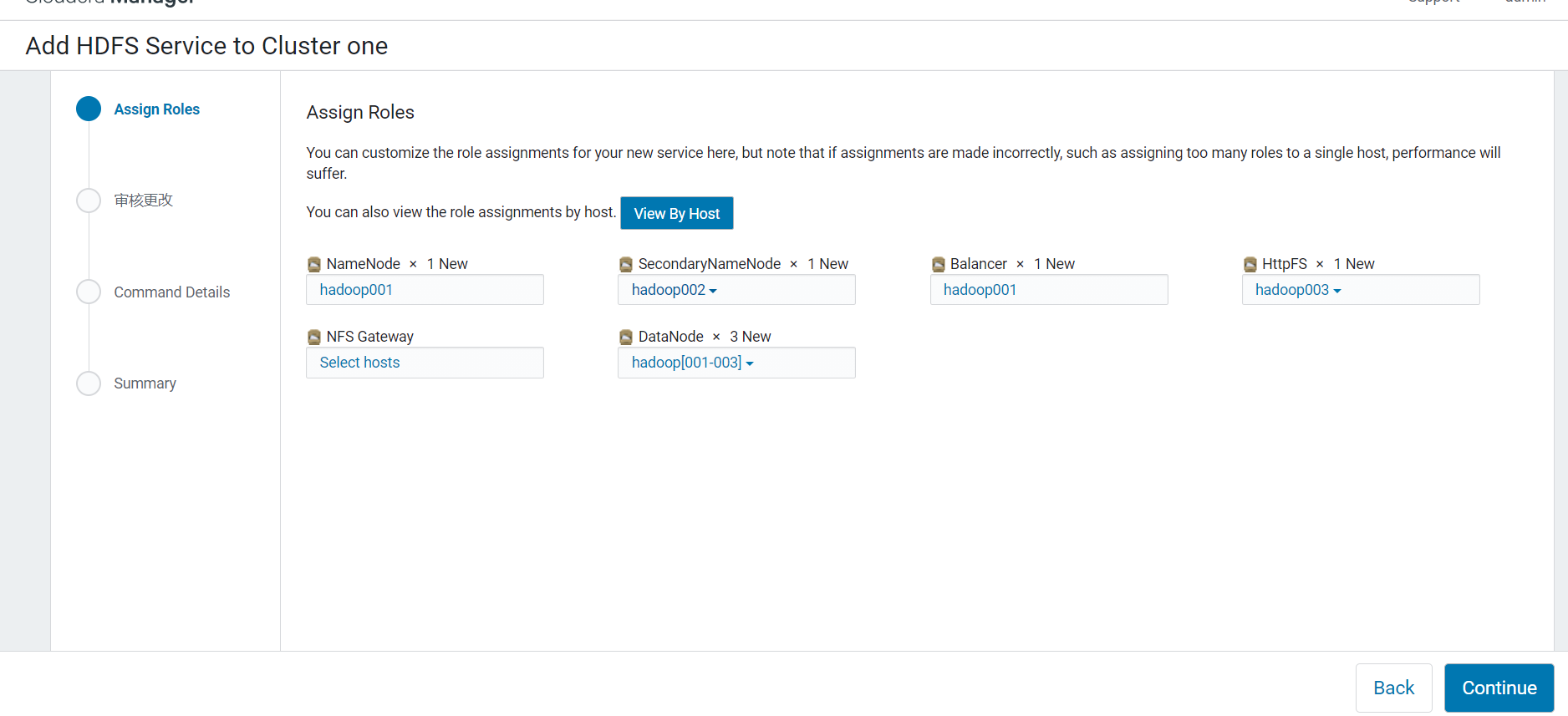
3.按照机器配置去分配各个组件的安装节点
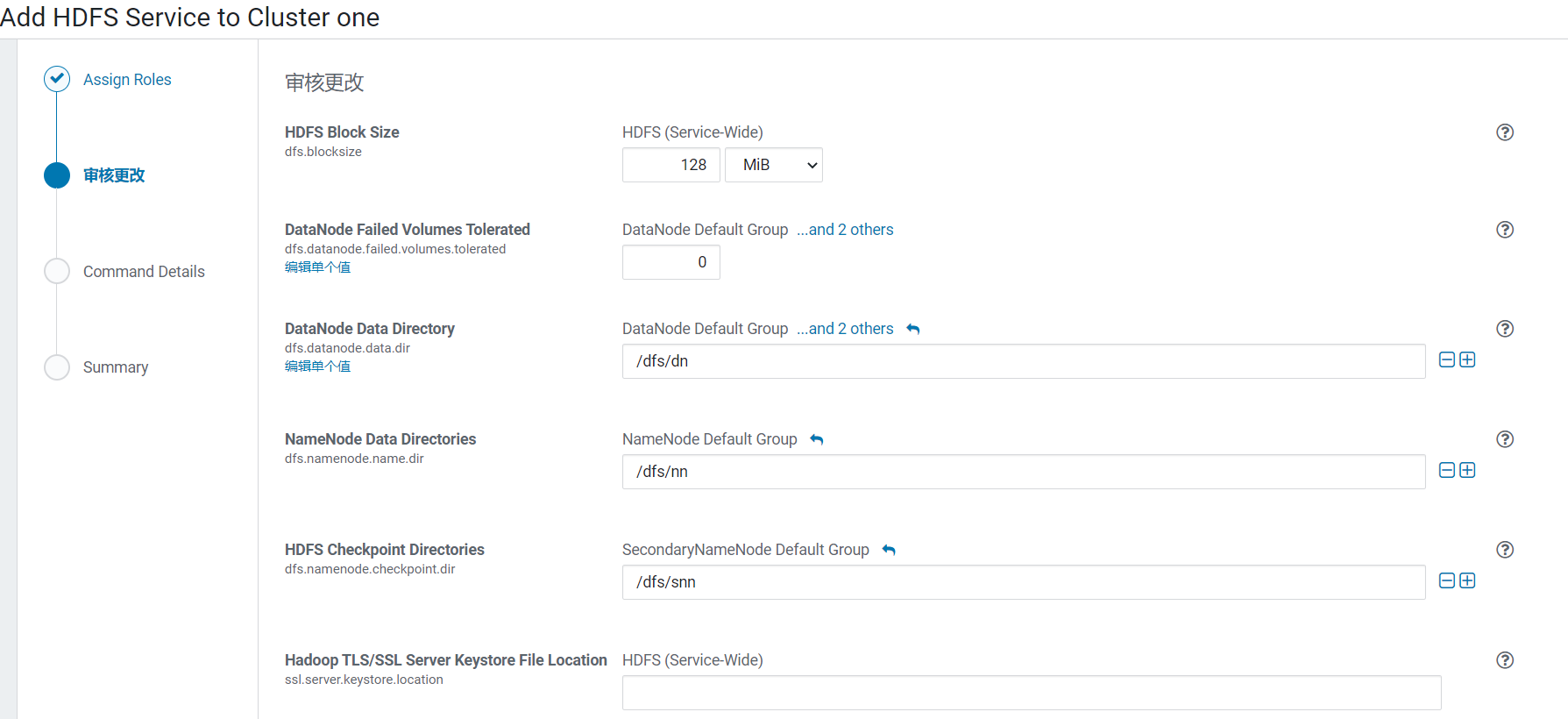
4.配置HDFS的基础配置
5.等待安装成功

6.安装成功后,在HDFS界面可以看到其相关信息了

7.关闭权限检查
HDFS默认能够执行写的用户是hdfs,所以当你在用其他用户角色在Linux上对HDFS有写操作的时候都会被拒绝执行,我们可以在HDFS配置里配置上对应的用户,或者直接关闭dfs的权限检查(dfs.permissions)。
在HDFS界面选择Configuration选项的时候,有时会卡在Loading…界面,此时需要再点击一次右边的Role Groups,再返回配置界面就能加载出来了,不知道是什么情况。
8.安装后测试
在Shell下执行命令进行测试:
1 | # 递归显示目录结构,去除-R为非递归 |
Yarn安装
1.选择Actions -> Add Service -> YARN

2.按照机器实际情况分配yarn的组件安装到哪台机器上

3.等待安装成功,安装成功后便能在主页面看到yarn集群的信息


4.安装成功后测试yarn是否能正常运行
1 | # π计算 |
Zookeeper安装
1.选择Actions -> Add Service -> ZooKepper,分配机器

2.配置dataDir快照目录与事务日志目录dataLogDir

3.等待ZooKeeper安装成功,安装成功后便能在主页面看到yarn集群的信息

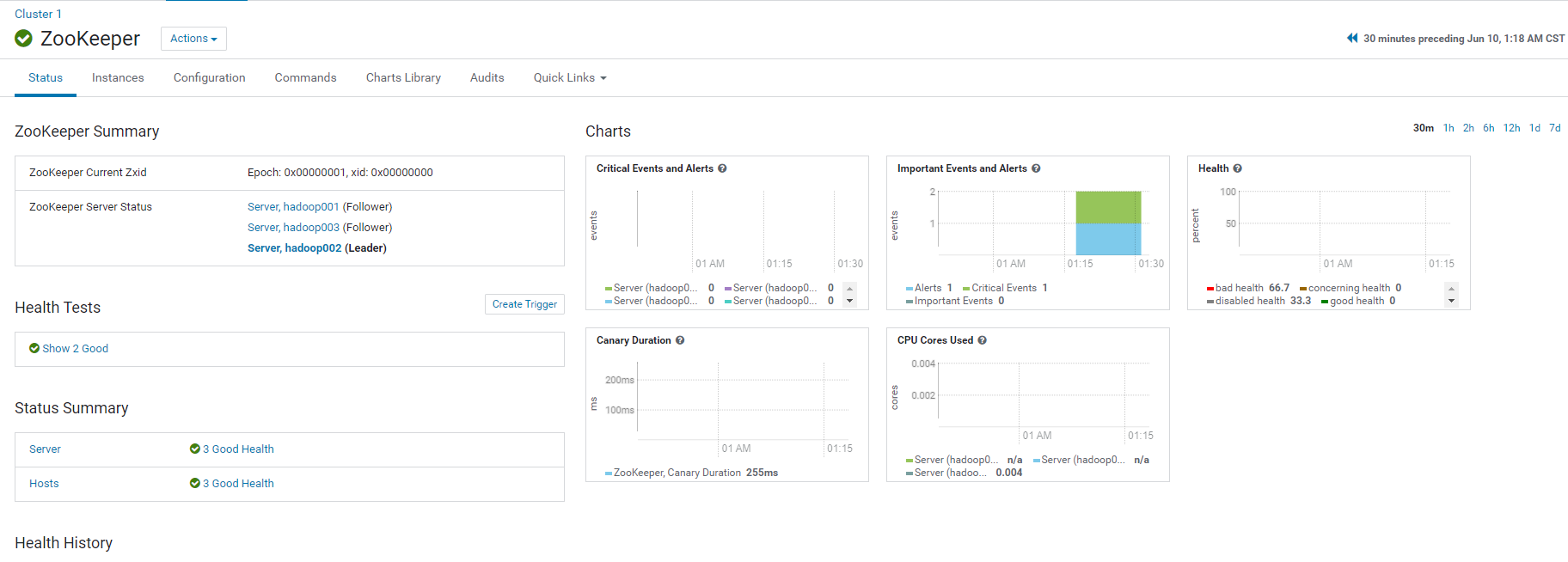
4.测试是否安装成功
1 | # 进入zk命令行 |
Hive安装
1.选择Actions -> Add Service -> Hive,选择依赖,并分配机器
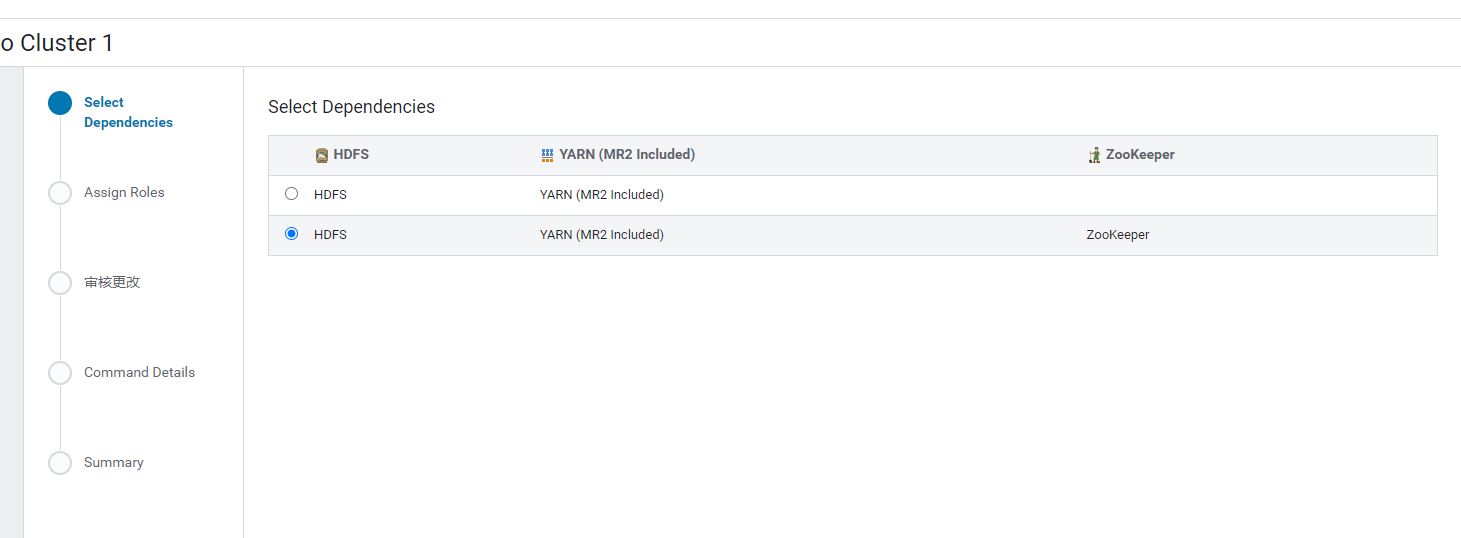
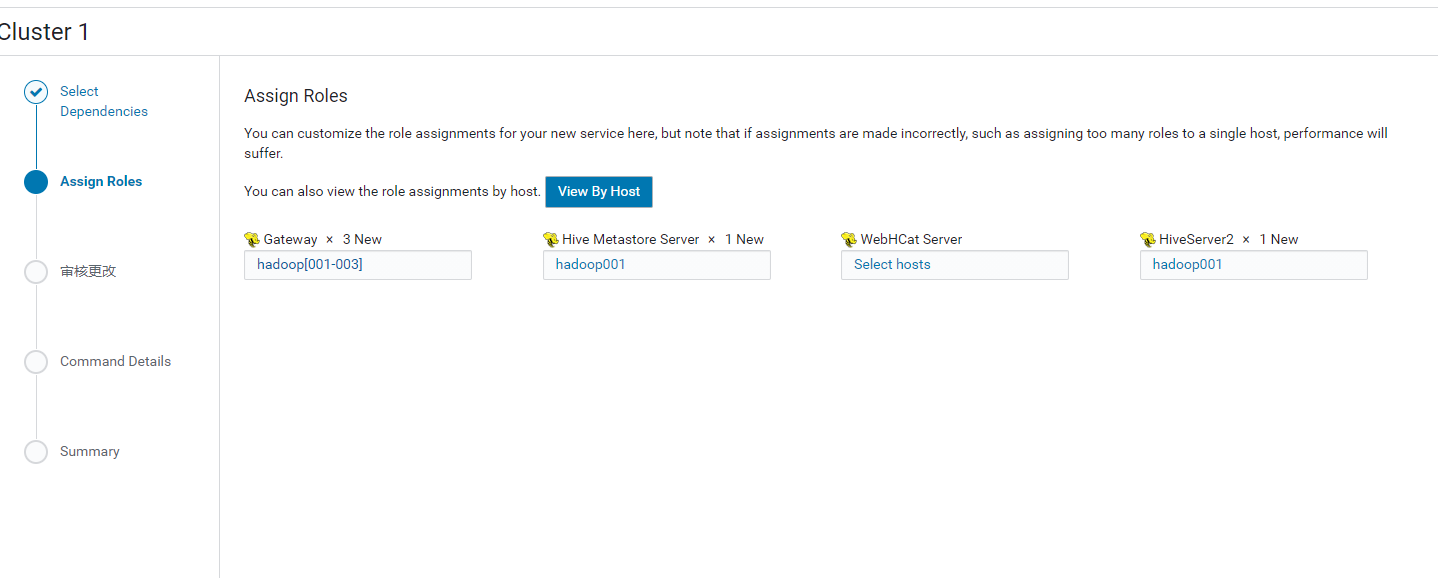
2.Hive元数据要配置MySQL数据库,在MySQL中配置对应的数据库信息
此处连接数据库,需要将MySQL驱动拷贝到Hive的lib目录下
1 | cp /opt/software/mysql-connector-java-5.1.40.jar /opt/cloudera/parcels/CDH/lib/hive/lib |
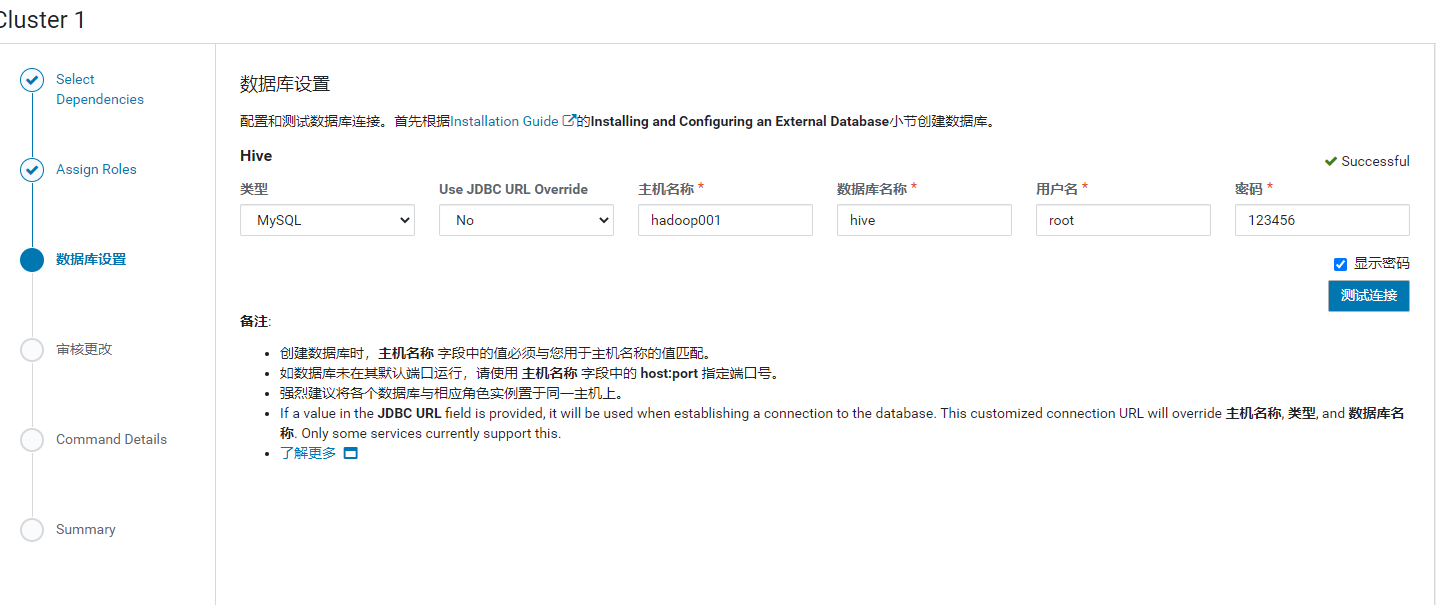
3.配置目录和端口,默认就好了

4.等待安装成功

如果没有拷贝MySQL驱动,就会报找不到驱动的错误
5.安装成功后就可以在主界面看到Hive的信息了

6.测试是否安装成功
登录Hive命令行客户端
1 | hive |
执行SQL测试
1 | create database testdb; |
Oozie安装
进入
Add Service to Cluster 1界面,选择Oozie,下一步Select Dependencies选择依赖,按需求选择配置Oozie Server安装到哪台机器,按需求选择
在MySQL中创建Oozie元数据数据库:
create database oozie;,然后在配置中填写。需要拷贝MySQL驱动到oozie的lib目录下才能让oozie连接到MySQL上:
1
2cp /opt/software/mysql-connector-java-5.1.40.jar /opt/cloudera/parcels/CDH/lib/oozie/lib/
cp /opt/software/mysql-connector-java-5.1.40.jar /var/lib/oozie/配置好oozie对应的数据目录
等待安装成功,安装成功后就能在主页面看到oozie的相关信息了。
Impala安装
- 进入
Add Service to Cluster 1界面,选择Impala,下一步 - 配置Impala组件安装到哪台机器,按需求选择
- 配置对应的安装目录,等待安装成功就OK了
- 测试时,输入命令
impala-shell进入操作界面,操作和Hive一样就OK了。
Kakfa安装
- 进入
Add Service to Cluster 1界面,选择Kafka,下一步 - 配置三台机器都安装Kafka Broker,其他的选择安装
- 选择kafka配置,配置
Java Heap Size of Broker为1024MiB,推荐是最小512,其他默认 - 点击完成,等待安装成功,安装成功后需要根据提示进行重启。
- 下面是Kafka常用命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 1.查看当前服务器中的所有topic
kafka-topics --zookeeper hadoop001:2181 --list
# 2.创建topic
# --topic 定义topic名
# --replication-factor 定义副本数
# --partitions 定义分区数
kafka-topics --zookeeper hadoop002:2181 \
--create --replication-factor 3 --partitions 3 --topic first-topic
# 3.删除topic (需要server.properties中设置delete.topic.enable=true否则只是标记删除。)
kafka-topics --zookeeper hadoop001:2181 \
--delete --topic first-topic
# 4.发送消息
kafka-console-producer --broker-list hadoop001:9092 --topic first-topic
> hello kafka
> hello world
# 5.消费消息(--from-beginning:会把主题中以往所有的数据都读取出来。)
kafka-console-consumer --bootstrap-server hadoop001:9092 --from-beginning --topic first-topic
# 6.查看某个topic的详情
kafka-topics --zookeeper hadoop001:2181 --describe --topic first-topic
# 7.修改分区数
kafka-topics --zookeeper hadoop001:2181 --alter --topic first-topic --partitions 6
Sqoop安装
- 进入
Add Service to Cluster 1界面,选择Sqoop 1 Client,下一步 - 配置选择哪台机器安装就好了,因为Sqoop是客户端类程序,所以是不需长驻内存的。
- 等待安装成功就OK了
- 可以输入如下常用命令测试是否能正常使用
1
2# 列出所有db
sqoop list-databases --connect jdbc:mysql://hadoop001:3306/ --username root --password 123456
Spark安装
- 进入
Add Service to Cluster 1界面,选择Spark,下一步 - 一直下一步安装就好了
- 在Shell中使用
spark-submit命令提交一个求Pi的任务,在http://host001:8088/cluster/可以查看到提交的任务
1 | spark-submit \ |
- 进入
http://host001:8088/cluster/,点击完成的任务,再点击Logs,在最下方就能看到输出的结果:Pi is roughly 3.1404391404391405
Hue安装
- 进入
Add Service to Cluster 1界面,选择Hue,下一步 - 配置选择哪台机器安装
- 创建独立数据库只作为Hue的元数据库
- 点击下一步就能等待安装成功了,访问:
http://hadoop001:8889/hue/accounts/login就能正常使用了